汉字编码概述:修订间差异
Dbzhang800(留言 | 贡献) 无编辑摘要 |
小无编辑摘要 |
||
| 第52行: | 第52行: | ||
<p class="line874">UNICODE使用平面来描述编码空间,每个平面分为256行,256列,相对于两字节编码的高低两个字节。 </p> | <p class="line874">UNICODE使用平面来描述编码空间,每个平面分为256行,256列,相对于两字节编码的高低两个字节。 </p> | ||
<p class="line862">UNICODE的第一个平面,称为<tt>BasicMultilingualPlane</tt>(基本多文种平面),简称BMP,由于BMP仅用两个字节表示,所以倍受青睐。 </p> | <p class="line862">UNICODE的第一个平面,称为<tt>BasicMultilingualPlane</tt>(基本多文种平面),简称BMP,由于BMP仅用两个字节表示,所以倍受青睐。 </p> | ||
<p class="line867">[[Image: | <p class="line867">[[Image:Unicode.png]] </p> | ||
<p>图2:Unicode编码图</p> | <p>图2:Unicode编码图</p> | ||
2007年5月23日 (三) 09:46的版本
汉字编码
本文作者:FireHare
授权许可:创作共用协议
编辑人员:FireHare
校对人员:FireHare
适用版本:所有
文章状态:完成
中 文文本的基本组成单位是汉字。目前我国汉字总数已超过6万字。汉字的数量大、字形复杂、同音字多、异体字多等特点给汉字在计算机内部的表示、处理、传输、 交换、输入、输出带来了一系列的问题,同时也给汉字编码工作带来了相当大的难度。我国汉字编码方案有多种,主要有以下几种编码方案:
1. GB2312-80 编码
GB2312码是中华人民共和国国家汉字信息交换用编码,全称《信息交换用汉字编码字符集--基本集》,由国家标准总局发布,1981年5月1日实施,通行于大陆。新加坡等地也使用此编码。
GB2312 收录简化汉字及符号、字母、日文假名等共7445个图形字符,其中汉字占6763个。GB2312规定“对任意一个图形字符都采用两个字节表示,每个字节 均采用七位编码表示”,习惯上称第一个字节为“高字节”,第二个字节为“低字节”。GB2312-80包含了大部分常用的一、二级汉字,和9区的符号。该 字符集是几乎所有的中文系统和国际化的软件都支持的中文字符集,这也是最基本的中文字符集。其编码范围是高位0xa1-0xfe,低位也是0xa1- 0xfe;汉字从0xb0a1开始,结束于0xf7fe。 GB2312 将代码表分为94个区,对应第一字节(0xa1-0xfe);每个区94个位(0xa1-0xfe),对应第二字节,两个字节的值分别为区号值和位号值加 32(2OH),因此也称为区位码。01-09区为符号、数字区,16-87区为汉字区(0xb0-0xf7),10-15区、88-94区是有待进一步 标准化的空白区。GB2312将收录的汉字分成两级:第一级是常用汉字计3755个,置于16-55区,按汉语拼音字母/笔形顺序排列;第二级汉字是次常 用汉字计3008个,置于56-87区,按部首/笔画顺序排列。故而GB2312最多能表示6763个汉字。
GB2312的编码范围为2121H-777EH,与ASCII有重叠,通行方法是将GB码两个字节的最高位置1以示区别。
<img title="attachment:GB2312-80.png" src="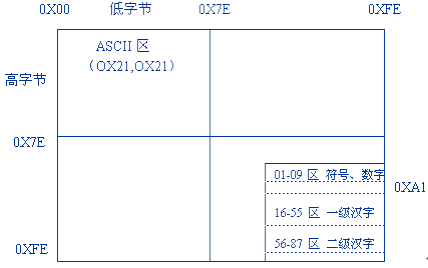 " alt="" />
" alt="" />
图1:GB2312编码图
图中位于ASCII区中的虚线区域即为原GB2312编码区域,右下角实线区域为平移后的GB2312编码区域。其中详细区位分布如下所示:
区号 字数 字符类别
01 94 一般符号
02 72 顺序号码
03 94 拉丁字母
04 83 日文假名
05 86 Katakana
06 48 希腊字母
07 66 俄文字母
08 63 汉语拼音符号
09 76 图形符号
10-15 备用区
16-55 3755 一级汉字,以拼音为序
56-87 3008 二级汉字,以笔划为序
88-94 备用区
2. GBK 和 GB18030 编码
由于BG2312表示的汉 字比较有限,因此一些偏僻汉字在GB2312中无法表示。随着计算机应用的普及,这个问题日益突出,我国的信息标准化委员会就对标准进行了扩充,得到了扩 充后的汉字编码方案GBK。它一方面向上兼容GB2312,另一方面将常用的繁体字填充到原编码标准中留下的空白码段中,使汉字数增加到20902个。值得注意的是GBK并不是一个国家标准,而只是一个规范,随着GB18030国家标准的发布,它将完成它的历史使命。GB18030采用变长编码,其中两字节部分与GBK完全兼容,共收录27484个汉字,总的编码数超过150万个码位。
3. Unicode 编码
随着互联网的迅速发展,进行数据交换的需求越来越大,不同的编码体系越来越成为信息交换的障碍,而且多种语言共存的文档不断增多,单靠ANSI代码页已很难解决这些问题,于是 Unicode 应运而生。
Unicode 采用两个字节编码体系,因此它允许表示65536个字符,这已能满足目前大多数场合的需要。前128个Unicode字符是标准的ASCII字符,接下来 的128个扩展的ASCII字符,其余的字符供不同语言的文字和符号使用。其版本V3.0于2000年公布,内容包括字母和符号10236个、汉字 27786个、韩文拼音11172个、造字区6400个、保留20249个,控制符65个。
UNICODE 同现在流行的代码页最显著不同点在于:UNICODE是两字节的全编码,对于ASCII字符它也使用两字节表示。代码页是通过高字节的取值范围来确定是 ASCII字符,还是汉字的高字节。如果发生数据损坏,某处内容破坏,则会引起其后汉字的混乱。UNICODE则一律使用两个字节表示一个字符,最明显的 好处是它简化了汉字的处理过程。
UNICODE 有双重含义,首先UNICODE是对国际标准ISO/IEC10646编码的一种称谓(ISO/IEC10646是一个国际标准,亦称大字符集,它是 ISO于1993年颁布的一项重要国际标准,其宗旨是全球所有文种统一编码),另外它又是由美国的HP、Microsoft、IBM、Apple等大企业 组成的联盟集团的名称,成立该集团的宗旨就是要推进多文种的统一编码。
UNICODE使用平面来描述编码空间,每个平面分为256行,256列,相对于两字节编码的高低两个字节。
UNICODE的第一个平面,称为BasicMultilingualPlane(基本多文种平面),简称BMP,由于BMP仅用两个字节表示,所以倍受青睐。

图2:Unicode编码图